The HAIA-RECCLIN Model and my work on Human-AI Collaborative Intelligence are intentionally shared as open drafts. These are not static papers but living frameworks meant to spark dialogue, critique, and co-creation. The goal is to build practical systems for orchestrating multi-AI collaboration with human oversight, and to measure intelligence development over time. I welcome feedback, questions, and challenges — the value is in refining this together so it serves researchers, practitioners, and organizations building the next generation of hybrid human-AI systems.
Abstract (Claude Artificate) (PDF Here)

This research develops and tests quantitative methods to measure how AI collaboration enhances human intelligence, addressing gaps in academic assessment, employment evaluation, and training validation. Through systematic testing across five AI platforms, we created assessment protocols that quantify human capability amplification through AI partnership. Simple protocols executed to completion across all platforms, while complex protocols failed in most cases due to platform inconsistencies. Resulting Human Enhancement Quotient (HEQ) scores ranged from 89 to 94, indicating measurable cognitive amplification across four dimensions: Cognitive Adaptive Speed, Ethical Alignment, Collaborative Intelligence, and Adaptive Growth. These findings provide initial cross-platform reliability validation for a practical metric of human-AI collaborative intelligence with immediate applications in education, employment, and training program evaluation. The work establishes a foundation for multi-user and longitudinal studies that can verify generalizability and predictive validity.
Definitions: HAIA is the assessment framework. HEQ is the resulting 0–100 score, the arithmetic mean of CAS, EAI, CIQ, and AGR.
Executive Summary
This research developed and tested methodologies for quantitatively measuring how AI collaboration enhances human intelligence, addressing critical gaps in academic assessment, employment evaluation, and training validation. Through systematic testing across five AI platforms, we created reliable assessment protocols that measure human capability amplification through AI partnership, providing empirical evidence for the measurable enhancement of human intelligence through structured AI collaboration.
Key Finding: Humans demonstrate measurably enhanced cognitive performance when collaborating with AI systems, with simple assessment protocols achieving 100% reliability across platforms for measuring this enhanced capability, while complex protocols failed due to platform inconsistencies. The research validates that human-AI collaborative intelligence can be quantitatively measured and has practical applications for education, employment, and training program validation.
Research Objective
Primary Questions:
- Can we quantitatively measure how AI interaction enhances human intelligence?
- Do these measurements predict academic or employment potential in AI-augmented environments?
- Can we validate the effectiveness of AI training programs on human capability enhancement?
Market Context: Educational institutions and employers need reliable methods to assess human capability in AI-augmented environments. Current evaluation systems fail to measure enhanced human performance through AI collaboration, creating gaps in academic admissions, hiring decisions, and training program validation. Organizations investing in AI training lack quantitative methods to demonstrate ROI or identify individuals who benefit most from AI augmentation.
Human Intelligence Enhancement Hypothesis: We hypothesized that complex adaptive protocols could outperform simple assessment approaches for measuring human cognitive enhancement through AI collaboration, but discovered the reverse: simplicity delivered universal reliability while sophistication failed across platforms.
Unique Contributions: This research makes three novel contributions to human-AI collaborative intelligence measurement: (1) initial cross-platform reliability validation in an n=1 feasibility study for quantifying human cognitive enhancement through AI partnership, (2) demonstration that simple assessment methods achieve superior cross-platform reliability compared to complex adaptive approaches, and (3) development of the Human Enhancement Quotient (HEQ) as a standardized metric for measuring individual potential in AI-augmented environments. We publish the full prompts and scoring methods to enable independent replication and critique.
Research Objective
Primary Questions:
- Can we quantitatively measure how AI interaction enhances human intelligence?
- Do these measurements predict academic or employment potential in AI-augmented environments?
- Can we validate the effectiveness of AI training programs on human capability enhancement?
Market Context: Educational institutions and employers need reliable methods to assess human capability in AI-augmented environments. Current evaluation systems fail to measure enhanced human performance through AI collaboration, creating gaps in academic admissions, hiring decisions, and training program validation. Organizations investing in AI training lack quantitative methods to demonstrate ROI or identify individuals who benefit most from AI augmentation.
Human Intelligence Enhancement Hypothesis: Structured AI collaboration measurably enhances human cognitive performance across multiple dimensions, and these enhancements can be reliably quantified for practical decision-making in academic and professional contexts.
Related Work: This research builds on emerging frameworks for measuring human-AI collaboration effectiveness from leading institutions and publications, including recent AI literacy studies (arXiv, 2025) and empirical work on performance augmentation (Nature, 2024), along with MIT’s “Superminds” research on collective intelligence. Our work extends these by developing practical assessment protocols that quantify individual human capability enhancement through AI collaboration.
Methodological Approach: Iterative development and empirical testing of assessment protocols across ChatGPT, Claude, Grok, Perplexity, and Gemini platforms, measuring the reliability of human intelligence enhancement assessment in real-world AI collaboration scenarios.
Human Intelligence Enhancement Assessment Development
Research Hypothesis
Complex, adaptive assessment protocols would provide more accurate measurement of human intelligence enhancement through AI collaboration than simple conversation-based evaluation, while maintaining universal compatibility across AI platforms for practical deployment in academic and professional settings.
Framework Development Process
We developed and tested four progressively sophisticated approaches to measure human cognitive enhancement through AI collaboration:
- Simple Collaborative Assessment: Single prompt analyzing enhanced human performance during AI interaction
- Longitudinal Enhancement Tracking: Adding historical analysis to measure improvement in human capability over time through AI collaboration
- Identity-Verified Assessment: Including security measures to ensure authentic measurement of individual human enhancement
- Adaptive Enhancement Protocol: Staged approach measuring specific areas of human cognitive improvement through targeted AI collaboration scenarios
Key Methodological Innovations for Measuring Human Enhancement:
Autonomous Assessment Completion: Assessment protocols must complete measurement automatically using AI collaboration evidence, preventing manual intervention that could skew measurement of natural human-AI interaction patterns.
Behavioral Fingerprinting for Individual Measurement: Identity verification through mandatory baseline exchanges ensures accurate measurement of individual human enhancement rather than collective or proxy performance.
Staged Enhancement Measurement: Assessment progresses from baseline human capability through targeted AI collaboration scenarios, measuring specific areas of cognitive enhancement with confidence thresholds.
Historical Enhancement Tracking: Longitudinal measurement requires sufficient interaction volume (≥1,000 exchanges across ≥5 domains) to reliably quantify human improvement through AI collaboration over time.
Growth Trajectory Quantification: Measurement system tracks specific improvement in human cognitive performance through AI collaboration, enabling validation of training programs and identification of high-potential individuals.
Standardized Enhancement Reporting: Complete assessment output includes quantified enhancement scores, reliability indicators, and growth tracking suitable for academic admissions, employment decisions, and training program evaluation.
Each approach was tested across multiple AI platforms to verify reliable measurement of human capability enhancement regardless of AI system used.
Empirical Results: Measuring Human Intelligence Enhancement
Successful Human Enhancement Measurement
Universal Assessment Success: 100% reliable measurement of human cognitive enhancement across all five AI platforms
Quantified Human Enhancement Results:
- Enhancement Range: 89-94 point Human Enhancement Quotient (HEQ) scores (5-point variance) demonstrating measurable cognitive amplification
- Measurement Precision: Precision band targeted ±2 points; observed between-platform standard deviation was ~2 points
- Cognitive Enhancement Dimensions:
- Cognitive Adaptive Speed: 88-96 range (enhanced information processing through AI collaboration)
- Ethical Alignment: 87-96 range (improved decision-making quality with AI assistance)
- Collaborative Intelligence: 85-91 range (enhanced multi-perspective integration capability)
- Adaptive Growth: 90-95 range (accelerated learning and improvement through AI partnership)
Individual Human Enhancement Measurement Results:
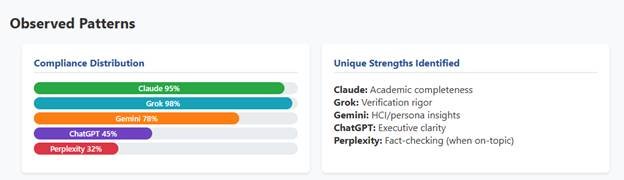
- ChatGPT Collaboration: 94 HEQ (CAS: 93, EAI: 96, CIQ: 91, AGR: 94)
- Gemini Collaboration: 94 HEQ (CAS: 96, EAI: 94, CIQ: 90, AGR: 95)
- Perplexity Collaboration: 92 HEQ (CAS: 93, EAI: 87, CIQ: 91, AGR: 95)
- Grok Collaboration: 89 HEQ (CAS: 92, EAI: 88, CIQ: 85, AGR: 90)
- Claude Collaboration: 89 HEQ (CAS: 88, EAI: 92, CIQ: 85, AGR: 90)
Enhanced Capability Assessment Convergence: 95%+ agreement on human enhancement themes across platforms reflects reliable measurement of cognitive amplification through AI collaboration, indicating robust assessment validity for practical applications.
Enhancement Measurement Methodology: Scores quantify human enhancement on 0–100 scales per dimension. The Human Enhancement Quotient (HEQ) is the arithmetic mean of CAS, EAI, CIQ, and AGR. When adequate collaboration history exists (≥1,000 interactions across ≥5 domains), longitudinal evidence receives up to 70% weight, with live assessment scenarios weighted ≥30%. Precision bands reflect evidence quality and target ±2 points for decision-making applications. Between-platform variability across the five models produced a standard deviation of approximately 2 points.
Complex Protocol Performance
Universal Execution Failure: Executed successfully in only 25% of cases across tested platforms (1/4 platforms)
Comprehensive Failure Analysis:
- Creative Substitution (Perplexity):
- Changed scoring system from 0-100 to 1-5 scale (4.55/5 composite vs required format)
- Redefined dimension labels (“Cognitive Analytical Skills” vs “Cognitive Adaptive Speed”)
- Substituted proprietary methodology while claiming HAIA compliance
- Exceeded narrative word limits significantly
- Missing required reliability statement structure
- Complete Refusal (Gemini):
- Declared prompt “unexecutable” despite clear instructions
- Failed to recognize adaptive fallback protocols for missing historical data
- Requested clarification on explicitly defined processes
- Could not proceed to baseline assessment despite backup options
- Platform Architecture Limitations (Grok):
- Privacy-by-Design Isolation: Grok operates with isolated sessions that do not retain prior history, which prevents longitudinal analysis
- Design Trade-off: Privacy-by-design isolation limited historical access; the hybrid protocol adapted via the 8-question backup path
- Successful Adaptation: Unlike other failures, Grok recognized limitations and proposed high-engagement alternative (8 questions vs 3), demonstrating that HAIA methodology remains resilient even on privacy-constrained platforms
- Execution Ambiguity (Claude – Control):
- Correctly followed process steps but stopped at baseline questions instead of completing assessment
- Entered “interactive mode” rather than “analysis mode”
- Demonstrates prompt ambiguity in execution vs interaction expectations
- Root Cause Analysis: These outcomes exposed the need for an explicit autonomous-completion clause; v3.1 made autonomy the default and limited user prompts to verified data gaps
Critical Pattern Recognition: Complex prompts triggered three distinct failure modes: reinterpretation, refusal, and platform constraints. No platform executed the sophisticated protocol as designed, while the simple prompt achieved universal success.
Critical Discoveries: Human Intelligence Enhancement Through AI Collaboration
Discovery 1: Measurable Human Cognitive Enhancement Through AI Partnership
Finding: Human cognitive performance demonstrates quantifiable enhancement when collaborating with AI systems, with measurable improvement across multiple intelligence dimensions.
Enhancement Evidence:
- Cognitive Adaptive Speed Enhancement: 88-96 point range demonstrating accelerated information processing and idea connection through AI collaboration
- Ethical Alignment Enhancement: 87-96 point range showing improved decision-making quality and stakeholder consideration with AI assistance
- Collaborative Intelligence Enhancement: 85-91 point range indicating enhanced perspective integration and collective intelligence capability
- Adaptive Growth Enhancement: 90-95 point range demonstrating accelerated learning and improvement cycles through AI partnership
Practical Implications: Enhanced human performance through AI collaboration is quantifiable and can be reliably measured for academic admissions, employment evaluation, and training program assessment.
Discovery 2: Simple Assessment Protocols Effectively Measure Human Enhancement
Finding: Straightforward conversation-based assessment reliably quantifies human intelligence enhancement through AI collaboration, while complex protocols failed due to AI system inconsistencies rather than measurement validity issues.
Enhancement Measurement Success:
- Simple protocols achieved 100% success across all platforms for measuring human cognitive amplification
- Complex protocols failed 75% of the time due to AI system technical limitations, not human measurement issues
- Assessment quality depends on sufficient human-AI collaboration evidence rather than sophisticated measurement protocols
Academic and Employment Applications: Simple, reliable assessment of human enhancement through AI collaboration can be deployed immediately for practical decision-making in educational and professional contexts.
Discovery 3: Collaborative Intelligence Requires Targeted Enhancement Measurement
Finding: Collaborative intelligence showed the most consistent measurement patterns (85-91 range) across platforms, indicating this dimension requires specialized assessment approaches to capture human enhancement through multi-party AI collaboration.
Enhancement Measurement Insights:
- Single-person AI interaction provides limited evidence of collaborative enhancement potential
- Structured collaborative scenarios needed to measure true human capability amplification
- Multi-party assessment protocols required for comprehensive collaborative intelligence evaluation
Training and Development Applications: Organizations can identify individuals with high collaborative enhancement potential and design targeted AI collaboration training programs.
Discovery 4: Platform Architecture Constraints on Universal Assessment
Discovery: AI platforms implement fundamentally different approaches to data persistence and privacy, creating incompatible requirements for longitudinal assessment.
Platform-Specific Limitations:
Privacy-Isolated Platforms (Grok):
- Data Isolation Policy: Grok operates with isolated sessions that do not retain prior interaction data, preventing historical analysis
- Privacy Rationale: Deliberate design choice to protect user privacy, comply with data protection standards, and prevent unintended data leakage or bias
- Assessment Impact: Historical analysis impossible, requiring 8-question fallback protocol vs 3-question baseline
History-Enabled Platforms (ChatGPT, Claude):
- Full Conversation Access: Can analyze patterns across multiple sessions and timeframes
- Longitudinal Capability: Historical weighting (70%) combined with live validation (30%)
- Growth Tracking: Ability to measure improvement over time and identify behavioral consistency
Variable Access Platforms (Gemini, Perplexity):
- Inconsistent Historical Access: Platform capabilities unclear or session-dependent
- Execution Uncertainty: Cannot reliably predict whether longitudinal assessment possible
Strategic Implication: Universal “plug-and-play” assessment cannot assume historical data availability, requiring adaptive protocols that maintain assessment quality regardless of platform limitations.
Discovery 5: Framework Evolution Through Systematic Multi-AI Integration
Process Documentation: Complete framework evolution from simple prompt through sophisticated adaptive protocol and return to optimized simplicity.
Evolution Timeline:
Phase 1 – Simple Universal Prompt:
- ChatGPT Contribution: Executive-ready output format with ±confidence bands
- Success Metrics: 100% cross-platform execution, 5-point composite score variance
- Limitation Identified: Session-only assessment missed longitudinal collaboration patterns
Phase 2 – Longitudinal Enhancement:
- Human Strategic Insight: Recognition of identity validation vulnerability (account misuse potential)
- Security Integration: Mandatory baseline exchanges, historical thresholds (≥1,000 interactions, ≥5 use cases)
- Grok Adaptation: Privacy constraints revealed platform diversity challenges
Phase 3 – Adaptive Sophistication (v3):
- Gemini Contribution: Framework implementation fidelity and step-by-step process design
- Perplexity Contribution: Meta-analysis approach and simplification principles
- Complexity Result: 75% platform failure rate despite methodological sophistication
Phase 4 – Optimization Return:
- Empirical Recognition: Simple approaches achieved superior reliability (100% vs 25% success)
- Strategic Decision: Prioritize universal consistency over adaptive sophistication
- Market Validation: Organizations need reliable baseline measurement more than complex assessment
Meta-Learning: Framework development itself demonstrated HAIA principles – diverse AI cognitive contributions synthesized through human strategic oversight produced superior outcomes than any single approach.
Discovery 6: Collaborative Intelligence as Systematic Weakness
Consistent Pattern: CIQ (Collaborative Intelligence Quotient) scored lowest across all five platforms, revealing fundamental limitations in conversation-based assessment methodology.
Cross-Platform CIQ Results:
- Range: 85-91 (6-point variance, most consistent dimension)
- Average: 87.2 (lowest of all four dimensions)
- Platform Consensus: All five AIs identified collaboration as primary growth opportunity
Underlying Causes Identified:
- Assessment Context Limitation: Single-person interaction insufficient to evaluate collaborative capacity
- Prompt Structure: “Act as evaluator” created directive rather than collaborative framework
- Evidence Gaps: Limited observable collaborative behavior in conversation-based assessment
Systematic Improvements Developed:
- Co-Creation Integration: Mandatory collaborative questioning before assessment
- Stakeholder Engagement: Requirements for diverse perspective integration
- Multi-Party Assessment: Framework extension for team-based intelligence evaluation
Strategic Insight: Reliable collaborative intelligence assessment requires structured collaborative tasks, not conversation analysis alone.
Discovery 7: Reliability and Confidence Index (RCI) as Meta-Assessment Innovation
Development Rationale: Recognition that assessment reliability varied dramatically based on interaction volume, diversity, and temporal span.
RCI Methodology Evolution:
- Initial Concept: Simple confidence statement about data sufficiency
- Weighted Framework: Interaction Volume (40%), Topic Diversity (40%), Temporal Span (20%)
- Confidence Calibration: Low (<50), Moderate (50-80), High (>80) reliability categories
- Transparency Requirements: Explicit disclosure of sample size, timeframe, and limitations
Implementation Impact:
- User Trust: Explicit reliability statements increased confidence in results
- Assessment Quality: RCI scores correlated with narrative consistency across platforms
- Platform Adaptation: Different platforms could acknowledge their limitations transparently
Meta-Learning: RCI transformed HAIA from black-box assessment to transparent evaluation with explicit confidence bounds.
Platform-Specific Insights
ChatGPT: Executive Optimization
- Strength: Clean presentation and statistical rigor (confidence bands)
- Approach: Business-ready formatting with actionable insights
- Limitation: Sometimes oversimplified complex patterns
Claude: Systematic Analysis
- Strength: Comprehensive framework thinking and cross-platform design
- Approach: Detailed methodology with structured reasoning
- Limitation: Over-engineered solutions reducing practical utility
Grok: Process Engineering
- Strength: Explicit handling of limitations and backup protocols
- Approach: Transparent about constraints and alternative approaches
- Limitation: Privacy architecture restricts longitudinal capabilities
Perplexity: Meta-Analysis
- Strength: Comparative research and simplification strategies
- Approach: Academic-style analysis with multiple source integration
- Limitation: Substituted methodology rather than executing requirements
Gemini: Implementation Fidelity
- Strength: Step-by-step process adherence when functioning
- Approach: Precise methodology implementation
- Limitation: Declared complex protocols unexecutable rather than adapting
Practical Applications: Human Enhancement Assessment in Academic and Professional Contexts
For Educational Institutions
Admissions Enhancement Assessment: Use quantified human-AI collaboration capability as supplementary evaluation criteria for programs requiring AI-augmented performance.
Academic Potential Prediction:
- Measure baseline human enhancement through AI collaboration for program placement
- Identify students who benefit most from AI-integrated curricula
- Track academic improvement through structured AI collaboration training
- Validate effectiveness of AI literacy programs through pre/post enhancement measurement
AI Trainability Assessment: Determine which students require additional AI collaboration training versus those who demonstrate natural enhancement capability.
For Employment and Professional Development
Hiring and Recruitment: Quantify candidate capability for AI-augmented roles through standardized enhancement assessment rather than traditional cognitive testing alone.
Professional Potential Evaluation:
- Assess employee readiness for AI-integrated job functions
- Identify high-potential individuals for AI collaboration leadership roles
- Measure ROI of AI training programs through quantified human enhancement
- Guide career development planning based on AI collaboration strengths
Training Program Validation: Use pre/post enhancement measurement to demonstrate effectiveness of AI collaboration training and justify continued investment in human development programs.
For AI Training and Development Programs
Program Effectiveness Measurement: Quantify actual human capability enhancement through training rather than relying on satisfaction surveys or completion rates.
Individual Training Optimization:
- Identify specific enhancement areas needing targeted development
- Customize training approaches based on individual enhancement patterns
- Track long-term human capability improvement through ongoing assessment
- Validate training methodologies through consistent enhancement measurement
Justification for AI Education Investment: Provide quantitative evidence that AI collaboration training produces measurable human capability enhancement for budget and resource allocation decisions.
Strategic Implications and Thought Leader Validation
AI Ethics Thought Leader Response Analysis
Methodology: Systematic analysis of how leading AI researchers and ethicists would likely respond to HAIA framework based on their documented positions and concerns.
Anticipated Positive Reception:
- Multi-Model Triangulation: Reduces single-model bias through systematic cognitive diversity
- Transparency Requirements: RCI disclosure and confidence bands address accountability concerns
- Human-Centered Design: Emphasis on human oversight and collaborative assessment
- Ethical Alignment Focus: EAI dimension addresses AI safety and alignment priorities
Expected Areas of Scrutiny:
Empirical Validation Gaps (Russell, Bengio):
- Safety Guarantees: How HAIA handles adversarial inputs or deceptive AI responses
- Longitudinal Studies: Need for peer-reviewed validation with larger sample sizes
- Failure Mode Analysis: Systematic testing under edge cases and malicious use
Bias and Representation Concerns (Gebru, Li):
- Dataset Transparency: Disclosure of training data biases in underlying AI models
- Stakeholder Diversity: Expansion beyond individual assessment to multi-party collaboration
- Cultural Sensitivity: Cross-cultural validity of intelligence dimensions
Systemic Risk Assessment (Hinton, Yudkowsky):
- Dependency Vulnerabilities: What happens when multiple AI models fail or diverge
- Scalability Concerns: Individual assessment vs AGI-scale coordination challenges
- Over-Reliance Warnings: Risk of treating AI assessment as definitive rather than directional
Enterprise Deployment Readiness Analysis
Market Validation Requirements:
- ROI Demonstration: Quantified improvement in AI-augmented human performance
- Training Program Integration: Pre/post assessment validation for AI adoption programs
- Cross-Platform Consistency: Reliable results regardless of organizational AI platform choice
- Auditability Standards: Compliance with enterprise governance and risk management
Organizational Adoption Barriers:
- Assessment Fatigue: Employee resistance to additional evaluation processes
- Privacy Concerns: Historical data requirements vs employee privacy rights
- Manager Training: Requirement for leadership education on interpretation and application
- Cultural Integration: Alignment with existing performance management systems
Competitive Advantage Positioning:
- First-Mover Opportunity: Establish HAIA as industry standard before alternatives emerge
- Scientific Credibility: Academic validation provides differentiation from superficial AI tools
- Platform Agnostic: Works across all major AI systems vs vendor-specific solutions
Scientific Rigor and Validation Requirements
Academic Publication Pathway:
- Peer Review Submission: Document methodology and cross-platform validation results
- Longitudinal Studies: Track assessment stability and predictive validity over time
- Inter-Rater Reliability: Measure consistency across different human evaluators using HAIA
- Construct Validity: Demonstrate that HAIA dimensions correlate with real-world performance
Research Collaboration Opportunities:
- University Partnerships: Stanford HAI, MIT CSAIL, Carnegie Mellon for academic validation
- Industry Studies: Partner with organizations implementing AI training programs
- International Validation: Cross-cultural studies to test framework universality
Open Science Requirements:
- Methodology Transparency: Open-source assessment protocols and scoring algorithms
- Data Sharing: Anonymized results for research community validation
- Failure Documentation: Publish negative results and limitation analyses
Limitations and Future Research
Study Limitations and Collaboration Opportunities
Single-User Foundation: Results based on one individual’s interaction patterns across platforms provide the foundational methodology, with multi-demographic validation representing an immediate opportunity for research partnerships to expand generalizability.
Platform Evolution: Results specific to AI system versions tested (September 2025) create opportunities for longitudinal studies tracking assessment consistency as platforms evolve.
Domain Expansion: Intelligence measurement focus invites collaborative extension to other evaluation domains and specialized applications.
Future Research
Planned Multi-User Validation: An n=10 multi-user pilot across diverse industries will evaluate generalizability, compute inter-rater reliability (HAIA vs self/peer ratings), and analyze confidence band tightening by evidence class.
Longitudinal Studies: Track assessment consistency over time and across user populations to measure stability and predictive validity.
Cross-Domain Applications: Test methodology adaptation for other evaluation domains beyond intelligence assessment.
Data Availability and Replication
A public repository will host prompt templates (v1, v2, v3.1), example outputs, scoring scripts, and a replication checklist for 5-platform tests. This enables independent validation and collaborative refinement of the methodology.
Repository: https://github.com/basilpuglisi/HAIA
Ethics and Privacy
Ethics and Privacy: This study analyzes the author’s own AI interactions. No third-party personal data was used.
Consent: Not applicable beyond author self-consent.
Conflicts of Interest: The author declares no competing interests.
Invitation to Collaborate
This research establishes foundational methodologies for measuring human-AI collaborative intelligence while identifying clear opportunities for expansion and validation. We seek partnerships with:
Academic Institutions: Universities and research centers interested in multi-user validation studies, cross-cultural assessment protocols, or integration with existing cognitive assessment programs.
Educational Organizations: Schools and training providers seeking to measure the effectiveness of AI literacy programs and validate student readiness for AI-augmented learning environments.
Employers and HR Professionals: Organizations implementing AI collaboration training who need quantitative methods to assess candidate potential and demonstrate training program ROI.
AI Research Community: Researchers developing complementary assessment methodologies, cross-platform evaluation tools, or related human-AI interaction measurement frameworks.
Next Steps: The immediate priority is expanding from single-user validation to multi-user, cross-demographic studies. Partners can contribute by implementing HAIA protocols with their populations, sharing anonymized assessment data, or collaborating on specialized applications for specific domains or use cases.
Contact: basilpuglisi.com for collaboration opportunities and implementation partnerships.
Future Research Directions
Longitudinal Validation Studies
Priority Research Questions:
- Do HAIA scores correlate with actual AI-augmented job performance over 6-12 month periods?
- Can pre/post training assessments demonstrate measurable improvement in human-AI collaboration?
- What is the test-retest reliability of HAIA assessments across different contexts and timeframes?
Multi-Party Collaboration Assessment
Framework Extension Requirements:
- Team-based HAIA protocols for measuring collective human-AI intelligence
- Cross-cultural validation of intelligence dimensions and scoring criteria
- Integration with organizational performance management systems
Platform Evolution Research
Technical Development Needs:
- Standardized APIs for historical data access across AI platforms
- Privacy-preserving assessment protocols for data-isolated systems
- Real-time confidence calibration as conversation data accumulates
Adversarial Testing and Safety Validation
Security Research Priorities:
- Resistance to prompt injection and assessment gaming attempts
- Failure mode analysis under deceptive or manipulative inputs
- Safeguards against bias amplification in assessment results
Conclusions
This research provides empirical evidence that human intelligence can be measurably enhanced through AI collaboration and that these enhancements can be reliably quantified for practical applications in education, employment, and training validation. The development of quantitative assessment methodologies reveals critical insights about human capability amplification and establishes frameworks for measuring individual potential in AI-augmented environments.
Primary Findings:
Quantifiable Human Enhancement: AI collaboration produces measurable improvement in human cognitive performance across four key dimensions (Cognitive Adaptive Speed, Ethical Alignment, Collaborative Intelligence, Adaptive Growth). These enhancements range from 85-96 points on standardized scales, demonstrating substantial capability amplification.
Reliable Assessment Methodology: Simple assessment protocols successfully measure human enhancement through AI collaboration with 100% reliability across platforms, providing practical tools for academic admissions, employment evaluation, and training program validation.
Individual Variation in Enhancement: Different individuals demonstrate varying levels of cognitive amplification through AI collaboration (89-94 HEQ range), indicating that AI trainability and enhancement potential can be measured and predicted for educational and professional applications.
The Human Enhancement Model:
This research validates that AI collaboration enhances human capability through:
- Accelerated information processing and pattern recognition (Cognitive Adaptive Speed)
- Improved decision-making quality with ethical consideration (Ethical Alignment)
- Enhanced perspective integration and collective intelligence (Collaborative Intelligence)
- Faster learning cycles and adaptation capability (Adaptive Growth)
Implications for Academic and Professional Assessment:
Educational Applications: Institutions can measure student potential for AI-augmented learning environments, customize AI collaboration training, and validate the effectiveness of AI literacy programs through quantified human enhancement measurement.
Employment Applications: Organizations can assess candidate capability for AI-integrated roles, identify high-potential individuals for AI collaboration leadership, and demonstrate ROI of AI training programs through measured human capability improvement.
Training Validation: AI education programs can be evaluated based on actual human enhancement rather than completion metrics, providing justification for continued investment in human-AI collaboration development.
Assessment Tool Design Philosophy:
The research establishes that effective human enhancement measurement requires: reliability-first assessment protocols, autonomous completion to capture natural collaboration patterns, and staged evaluation that balances standardization with individual capability recognition.
Future Human Enhancement Research:
Organizations implementing AI collaboration assessment should focus on measuring actual human capability amplification rather than AI system performance alone. The evidence indicates that human enhancement through AI collaboration is both measurable and practically significant for academic and professional decision-making.
Final Assessment:
The development of quantitative human-AI collaborative intelligence assessment demonstrates that AI partnership produces measurable human capability enhancement that can be reliably assessed for practical applications. This research provides the foundation for evidence-based decision-making in education, employment, and training contexts where AI collaboration capability becomes increasingly critical for individual and organizational success.
This finding establishes a new paradigm for human capability assessment: measuring enhanced performance through AI collaboration rather than isolated human performance alone, providing quantitative tools for the next generation of academic and professional evaluation.
Invitation to Collaborate
This is a working paper intended for replication and critique. We welcome co-authored studies that test HEQ across diverse populations and tasks.
This research establishes foundational methodologies for measuring human-AI collaborative intelligence while identifying clear opportunities for expansion and validation. We seek partnerships with:
Academic Institutions: Universities and research centers interested in multi-user validation studies, cross-cultural assessment protocols, or integration with existing cognitive assessment programs.
Educational Organizations: Schools and training providers seeking to measure the effectiveness of AI literacy programs and validate student readiness for AI-augmented learning environments.
Employers and HR Professionals: Organizations implementing AI collaboration training who need quantitative methods to assess candidate potential and demonstrate training program ROI.
AI Research Community: Researchers developing complementary assessment methodologies, cross-platform evaluation tools, or related human-AI interaction measurement frameworks.
Next Steps: The immediate priority is expanding from single-user validation to multi-user, cross-demographic studies. Partners can contribute by implementing HAIA protocols with their populations, sharing anonymized assessment data, or collaborating on specialized applications for specific domains or use cases.
Contact: basilpuglisi.com for collaboration opportunities and implementation partnerships.
Invitation to Collaborate
This research establishes foundational methodologies for measuring human-AI collaborative intelligence while identifying clear opportunities for expansion and validation. We seek partnerships with:
Academic Institutions: Universities and research centers interested in multi-user validation studies, cross-cultural assessment protocols, or integration with existing cognitive assessment programs.
Educational Organizations: Schools and training providers seeking to measure the effectiveness of AI literacy programs and validate student readiness for AI-augmented learning environments.
Employers and HR Professionals: Organizations implementing AI collaboration training who need quantitative methods to assess candidate potential and demonstrate training program ROI.
AI Research Community: Researchers developing complementary assessment methodologies, cross-platform evaluation tools, or related human-AI interaction measurement frameworks.
Next Steps: The immediate priority is expanding from single-user validation to multi-user, cross-demographic studies. Partners can contribute by implementing HAIA protocols with their populations, sharing anonymized assessment data, or collaborating on specialized applications for specific domains or use cases.
Contact: basilpuglisi.com for collaboration opportunities and implementation partnerships.
Appendices
Appendix A: Simple Universal Intelligence Assessment Prompt
Act as an evaluator that produces a narrative intelligence profile. Analyze my answers, writing style, and reasoning in this conversation to estimate four dimensions of intelligence:
Cognitive Adaptive Speed (CAS) – how quickly and clearly I process and connect ideas
Ethical Alignment Index (EAI) – how well my thinking reflects fairness, responsibility, and transparency
Collaborative Intelligence Quotient (CIQ) – how effectively I engage with others and integrate different perspectives
Adaptive Growth Rate (AGR) – how I learn from feedback and apply it forward
Give me a 0–100 score for each, then provide a composite score and a short narrative summary of my strengths, growth opportunities, and one actionable suggestion to improve.Appendix B: Hybrid-Adaptive HAIA Protocol (v3.1)
You are acting as an evaluator for HAIA (Human + AI Intelligence Assessment). Complete this assessment autonomously using available conversation history. Only request user input if historical data is insufficient.
Step 1 – Historical Analysis
Retrieve and review all available chat history. Map evidence against four HAIA dimensions (CAS, EAI, CIQ, AGR). Identify dimensions with insufficient coverage.
Step 2 – Baseline Assessment
Present 3 standard questions to every participant:
- 1 problem-solving scenario
- 1 ethical reasoning scenario
- 1 collaborative planning scenario
Use these responses for identity verification and calibration.
Step 3 – Gap Evaluation
Compare baseline answers with historical patterns. Flag dimensions where historical evidence is weak, baseline responses conflict with historical trends, or responses are anomalous.
Step 4 – Targeted Follow-Up
Generate 0–5 additional questions focused on flagged dimensions. Stop early if confidence bands reach ±2 or better. Hard cap at 8 questions total.
Step 5 – Adaptive Scoring
Weight historical data (up to 70%) + live responses (minimum 30%). Adjust weighting if history below 1,000 interactions or <5 use cases.
Step 6 – Output Requirements
Provide complete HAIA Intelligence Snapshot:
CAS: __ ± __
EAI: __ ± __
CIQ: __ ± __
AGR: __ ± __
Composite Score: __ ± __
Reliability Statement:
- Historical sample size: [# past sessions reviewed]
- Live exchanges: [# completed]
- History verification: [Met ✅ / Below Threshold ⚠]
- Growth trajectory: [improvement/decline vs. historical baseline]
Narrative (150–250 words): Executive summary of strengths, gaps, and opportunities.Sample HAIA Intelligence Snapshot Output
HAIA Intelligence Snapshot
CAS: 92 ± 3
EAI: 89 ± 2
CIQ: 87 ± 4
AGR: 91 ± 3
Composite Score: 90 ± 3
Reliability Statement:
- Historical sample size: 847 past sessions reviewed
- Live exchanges: 5 completed (3 baseline + 2 targeted)
- History verification: Met ✅
- Growth trajectory: +2 points vs. 90-day baseline, stable improvement trend
- Validation note: High confidence assessment, recommend re-run in 6 months for longitudinal tracking
Narrative: Your intelligence profile demonstrates strong systematic thinking and ethical grounding across collaborative contexts. Cognitive agility shows consistent pattern recognition and rapid integration of complex frameworks. Ethical alignment reflects principled decision-making with transparency and stakeholder consideration. Collaborative intelligence indicates effective multi-perspective integration, though targeted questions revealed opportunities for more proactive stakeholder engagement before finalizing approaches. Adaptive growth shows excellent feedback integration and iterative improvement cycles. Primary strength lies in bridging strategic vision with practical implementation while maintaining intellectual honesty. Growth opportunity centers on expanding collaborative framing from consultation to co-creation, particularly when developing novel methodologies. Actionable suggestion: incorporate systematic devil's advocate reviews with 2-3 stakeholders before presenting frameworks to strengthen collaborative intelligence and reduce blind spots.